Over the years, I have developed a bit of a love-hate relationship with make. On the plus side, it is ubiquitous, preinstalled on most UNIX systems, and widely used. On the other hand, its syntax can feel arcane and clunky, and it can prove hard to debug.
In this article, I will go over the basic make concepts, and the set of best practices I've come to embrace as my own, to make make enjoyable to use.
Let's start with the beginning.
Getting started with make
The step structure
make is a build system: a piece of tooling allowing you to define steps to build your project. It should make sure to only rebuild what needs to be rebuilt, to keep build time as short as possible. All these steps are defined in a file named Makefile, usually located at the root of your project.
A make step has the following syntax:
target: [space separated dependencies]
shell instructions
...
By default, make assumes that a target is a file, and will build it by executing the shell instructions associated with that target, after it has executed the shell instructions associated with the possible target dependencies (if any).
Let's have a look at a simple example in which we will build this hello.c file into a hello binary, using the gcc compiler.
#include <stdio.h>
int main() {
printf("hello world\n");
return 0;
}
We define the following Makefile:
hello: hello.c
gcc hello.c -o hello
We can then run make hello to compile the hello binary, after which we run it:
$ make hello
gcc hello.c -o hello
$ ./hello
hello world
When we ran make hello, make detected that the hello file wasn't found on disk, and built it by running gcc hello.c -o hello.
What happens if we re-run the same command now?
$ make hello
make: `hello' is up to date.
make detected that hello.c hadn't changed since last time hello was built, and thus did nothing. If we change hello.c to print hello bobbytables instead of hello world, make will see that the file had changed and will happily rebuild the binary:
#include <stdio.h>
int main() {
- printf("hello world\n");
+ printf("hello bobbytables\n");
return 0;
}
$ make hello
gcc hello.c -o hello
$ ./hello
hello bobbytables
Phony targets
Say now that you'd like to define a run step, that will simply run the binary:
hello:
gcc -o hello hello.c
run: hello
./hello
$ make run
./hello
hello world
The issue here, is that run does not represent a file on disk. To avoid confusing make, we mark this step as being PHONY, aka not a file make needs to build. This will make sure the associated shell instructions are always executed.
hello:
gcc -o hello hello.c
.PHONY: run
run: hello
./hello
Default target
We can define what step should be run when invocating make without any argument by using .DEFAULT_GOAL:
.DEFAULT_GOAL = run
hello:
gcc -o hello hello.c
.PHONY: run
run: hello
./hello
$ make
./hello
hello world
We can hide the command being executed by prefixing it with @.
.DEFAULT_GOAL = run
hello:
gcc -o hello hello.c
.PHONY: run
run: hello
@./hello
$ make
hello world
And with that, we now know just enough to get started for real.
My best practices
Makefile auto-documentation as the default step
Ever since I stumbled on this article, I have made sure to auto-document all my Makefiles, to help with discoverability. This works by adding a one-liner explanation of the "public" targets (the one a contributor might find themselves executing) after a ##. We then define a help target that will parse the current Makefile, extract all the target names and associated comments, and format them nicely. The finishing touch is to make help the default target, to make it extra easy for a newcomer to understand what can be built with your Makefile.
.DEFAULT_GOAL = help
...
run: admin-statics build ## Run the app
...
help: ## Display help
@grep -E '^[a-zA-Z_-]+:.*?## .*$$' $(MAKEFILE_LIST) | sort | awk 'BEGIN {FS = ":.*?## "}; {printf "\033[36m%-30s\033[0m %s\n", $$1, $$2}'
This is what the output looks like for the 5esheets project:
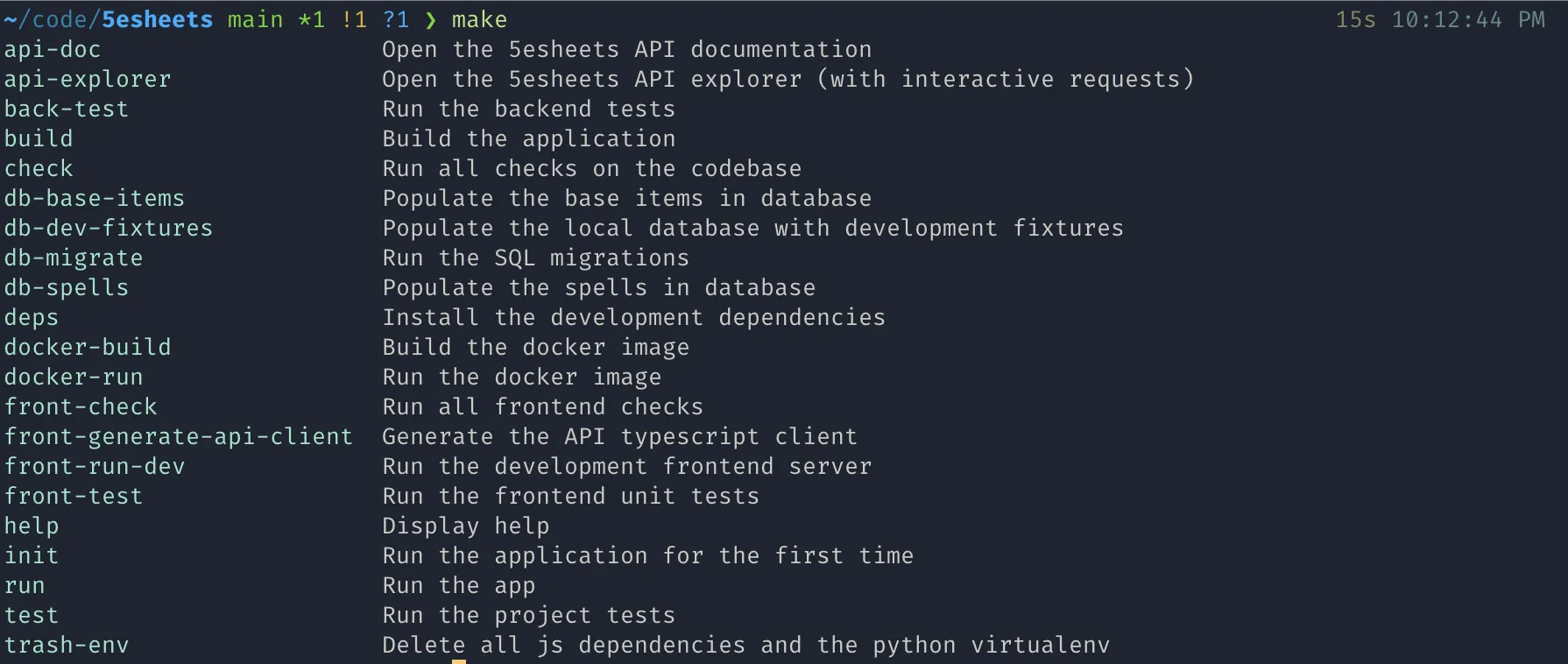
Tell what's happening, not how
I personally like to have each step include a short explanation of what it is doing, and hide the actual shell command, which I find of low value.
deps-python: poetry.lock
@echo "\n[+] Installing python dependencies"
@poetry install
In that example, when the target executes, I see [+] Installing python dependencies, as well at the command output, but not the poetry install command itself. I find that communicating the intent is clearer and more self-explanatory than taking screen real-estate by displaying the nitty-gritty details.
Define commonalities in variables
When I find myself repeating things too much in various rules, this is when I start using variables. For example, instead of writing many rules that hardcode a given directory name in them, I define that directory name in a variable. This makes it easier to keep the Makefile valid when the project structure evolves.
app-root = dnd5esheets
black:
@echo "\n[+] Reformatting python files"
@poetry run black --check $(app-root)/
mypy:
@echo "\n[+] Checking Python types"
@poetry run mypy $(app-root)/
ruff:
@echo "\n[+] Running linter"
@poetry run ruff $(app-root)/
Keep all paths in the Makefile
Some of my targets are oftentimes generated via scripts (usually python), which process some input and dump their result to a target file. I find that passing the output file path to the script (instead of hardcoding the file path in the script) allows the Makefile to be more self-contained and makes it easier to rename files without having to update both the Makefile and the script.
$(data-dir)/translations-items-fr.json:
@echo "\n[+] Fetching items french translations"
@curl -s $(fr-translations-data-dir)/dnd5e.items.json > $(data-dir)/translations-items-fr.json
$(data-dir)/items-base.json: $(data-dir)/translations-items-fr.json
@echo "\n[+] Fetching base equipment data"
@curl -s $(5etools-data-dir)/items-base.json | ./scripts/preprocess_base_item_json.py $(data-dir)/items-base.json
We can then avoid repeating ourselves by leveraging the $@ symbol, which expands to the name of the target being generated.
$(data-dir)/translations-items-fr.json:
@echo "\n[+] Fetching items french translations"
@curl -s $(fr-translations-data-dir)/dnd5e.items.json > $@
$(data-dir)/items-base.json: $(data-dir)/translations-items-fr.json
@echo "\n[+] Fetching base equipment data"
@curl -s $(5etools-data-dir)/items-base.json | ./scripts/preprocess_base_item_json.py $@
Generate a visual representation of the Makefile
I like having a visual representation of the dependencies of each target. It allows me to debug why some targets are not being rebuilt when they should, or are always being rebuilt when they shouldn't be. I find that it it also helps when getting started with the project for the first time. I leverage the makefile2dot Python package for this:
doc/makefile.png: Makefile
@echo "\n[+] Generating a visual graph representation of the Makefile"
@poetry run makefile2dot -o $@
You'll notice that this target depends on the Makefile itself, as it needs to be re-generated as the Makefile evolves.

Keep things readable
This is probably my most fundamental best practice.
Over the years, I have realized that I'm not smart enough to maintain a cryptic-looking Makefile. I my view, articles such as this one steer the reader into producing "smart" Makefiles that are non obvious to reason about (especially the last example). I need to be able to read a target's logic and understand what it does months after having written it. The same way, I won't hesitate to repeat myself and avoid variables when I think the output looks clearer. I try not to use "magic variables" too much.
There's a delicate balance to be struck between expressibility and readability, and I think readability should always win. You'll thank yourself later.
Comments